
- Log in to the Azure portal at https://portal.azure.com ➢ navigate to the Azure Databricks workspace you created in Exercise 3.14 ➢ select the Admin Console link by expanding the drop‐down list below your identity in the upper‐right corner ➢ click the Add User button ➢ enter an email address of a user in your Azure Active Directory tenant ➢ and then click OK. The user should have Workspace and Databricks SQL access.
- Select Compute from the navigation menu ➢ click the Create Cluster/Compute button ➢ and then configure the cluster as shown in Figure 8.41.
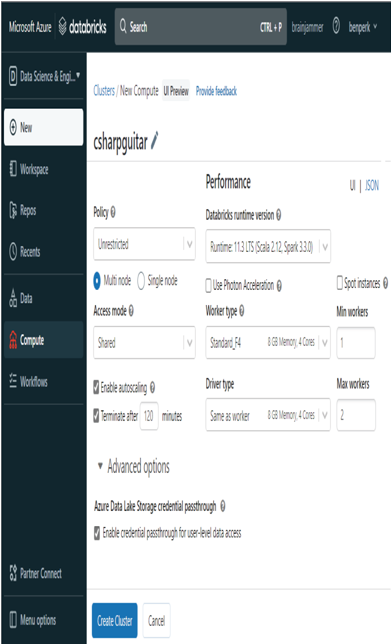
FIGURE 8.41 Creating a shared, credential passthrough spark cluster
- Click the Create Cluster button ➢ click the Cluster link on the Compute page ➢ click the More … button ➢ select Permissions from the drop‐down list ➢ select the user from step 1 from the Select User, Group or Service Principal drop‐down list ➢ set Can Manage as the permission ➢ click the + Add button ➢ and then click Save.
- Download the NormalizedBrainwavesSE.parquet file from the Chapter08/Ch08Ex10 directory on GitHub ➢ and then upload the file into the ADLS container you created in Exercise 3.1. Remember the location.
- Navigate to the Azure Databricks workspace you created in Exercise 3.14 ➢ select Access Control (IAM) from the navigation menu ➢ select the + Add menu item ➢ select Add Role Assignment from the drop‐down ➢ select the Contributor role ➢ click Next ➢ select the User, Groups, or Service Principal radio button ➢ select the + Select members link ➢ search for and select the user added in step 1 ➢ click the Select button ➢ and then click the Review + Assign button. The user will be added to the Contributor role, as shown in Figure 8.42.
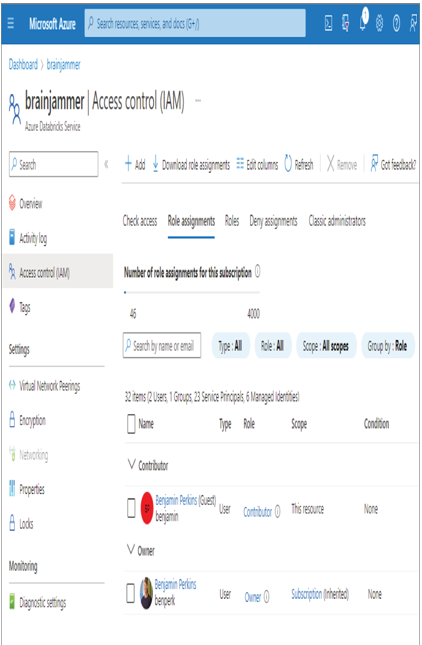
FIGURE 8.42 Adding a user to an Azure Databricks workspace using RBAC
- Add the same user from step 1 to the Storage Blob Data Reader RBAC role to the storage account created in Exercise 3.1 and the account you uploaded the Parquet file to in step 4, similar to that shown in Figure 8.17.
- Access the Azure Databricks workspace using the URL provided on the Overview Azure Databricks blade, similar to the following. Use the credentials of the user from step 1.
https://.azuredatabricks.net - Create a new notebook ➢ connect the notebook to the cluster created in step 2 ➢ execute the following Python code, which is available in the brainjammer.ipynb file in the Chapter08/Ch08Ex10 on GitHub:
rawReadings = “abfss://@.dfs.core.windows.net/*.parquet”
rawReadingsDF = spark.read.option(“header”,”true”).parquet(rawReadings)
rawReadingsDF.createOrReplaceTempView(“TmpREADING”)
spark.sql(“SELECT * FROM TmpREADING”).limit(5).show()
The most critical part of Exercise 8.10 is the action you performed in step 2 when creating the cluster (refer to Figure 8.41). Selecting the Enable Credential Passthrough for User‐level Data Access check box in the Advanced Options section worked a lot of magic behind the scenes. Here, the magic is the retrieval and passing of a token from the Azure Databricks workspace to the resource you are trying to access when running the Python code. As the creator of the workspace, you would have had access without the need for a shared access mode cluster and the addition of a new user to the platform. However, as the creator of the Azure Databricks workspace and the ADLS container, you would not have seen which permissions are required in order to run queries and code from a notebook.
Those permissions were for the Contributor role on the Azure Databricks workspace and Storage Blob Data Reader role on the Azure storage account that has the ADLS container. This also calls out the important security concept of granting the least amount of access required to perform the activity. As the creator, you are added to the Owner RBAC group, and you are probably also the administrator of the Subscription; so, after enabling credential passthrough, you would be able to perform your data analysis from the Azure Databricks spark cluster. However, you would not want to grant other members of your team that same level of access. Instead, provide the bare minimum required. Also, once the permissions are no longer needed, remove them. For example, if a member leaves the team or company, you do not want them to have access to either the product or the data.
Another topic for this section has to do with using managed identities when creating linked services from Azure Synapse Analytics. In most of the exercises you performed that used a linked service, you set the authentication type to Account Key, which is then used as part of a connection string. This authentication approach is secure; however, a better approach would be to use a system‐ or user‐assigned managed identity. To achieve that, you must add those managed identities to the RBAC role in the Azure product that the linked service is connecting to. Another option is storing the access key in an Azure key vault instead of using the connection string option. Complete Exercise 8.11, where you will configure a linked service to retrieve an authentication key from Azure Key vault.

